{kind=link}
(Information Management: A Proposal; Tim Berners-Lee, CERN; March 1989, May 1990) 한글 번역본입니다.
원래 1989년 3월 맥워드(또는 맥을 위한 워드?) 문서로 작성되었다가 나중에 1990년 5월로 날짜가 추가된 것을 제외하면 바뀐 것 없이 다시 배포된 HTML에 대한 안내 글이다. 역사적인 관심이 있기 때문에 제공할 뿐. 도표는 약간 어지럽지만 아래쪽에 링크된 글을 통해 다양한 버전을 구할 수 있다. 글 내용은 바꾸지 않았고, 심지어 잘못 메겨진 그림번호나 완결되지 않은 참고자료 목록까지 그대로 두었다.
이 문서는 CERN 경영진에게 만국 공통의 하이퍼텍스트 시스템이 CERN의 관심사가 되어야 한다고 설득하기 위해 작성되었다. 이때 당시에는 “Mesh[그물망]”라고 밖에는 이름 짓지 않았지만 -- 1990년에 코드를 짤 때는 “World Wide Web"이라 부르기로 결정했다.
다른 버전들도 볼 수 있다 :
• 위 문서를 기초로 작성된 RTF 파일, 따 올 수 있는 그림이 들어 있다.
• 위의 RTF 파일을 근거로 1998년에 MS워드를 이용해 만들어진 Microsoft 형식의 HTML 파일, 화소로 그려진 그림이 있다.
© 팀 버너스-리 1989, 1990, 1996, 1998. 모든 권리는 유보된다.
정보 처리: 한 가지 제안 편집
팀 버너스-리, CERN
1989년 3월, 1990년 5월
이 제안은 CERN[유럽 입자물리학 연구소]의 가속기와 실험에 대한 일반 정보 처리를 다룬다. 복잡하게 진화하고 있는 시스템에서 발생하는 정보손실 문제를 언급하고, 분산된 하이퍼텍스트 시스템에 기초한 대안을 도출한다.
{kind=link}
개요 편집
CERN에서 다가올 LHC[거대 강입자 가속기, 2008년에 첫 시험 가동됨] 시대의 미래에 대한 토론중 상당수가 다음 문제에 봉착한다 - 좋아, 그런데 우리가 어떻게 그 큰 프로젝트의 궤적을 추적할 수 있지? 이 제안은 그런 질문에 한 가지 대안을 제공한다. 먼저, 이 글에서는 CERN에서의 정보 접근 문제를 다룬다. 그리고 링크로 연결된 정보시스템의 구상을 제안한 후, 이와 달리 융통성 없는 정보탐색 방법들을 비교한다.
그 다음엔 ‘하이퍼텍스트’로 알려진 비선형[불연속적인] 문서 시스템에 대한 나의 짧은 경험을 요약하고, 이런 시스템을 도입하기 위해 CERN이 해야 할 일과 기업이 제공해야 할 것을 설명한다. 마지막으로 우리가 개인적, 집단적으로 어떤 것을 창조해 놓았는지를 알아보기 위해, 지금 우리 자신이 하이퍼텍스트에 몰입하는 단계를 제안한다.
CERN에서의 정보손실 편집
CERN은 굉장한 조직이다. 여기에는 수천 명의 사람들이 소속되어 있고, 그들 중 다수는 매우 창조적이며, 모두가 공통의 목표를 향해 일하고 있다. 그들이 명목상 계층적 관리구조에 따라 조직되어 있지만, 그것 때문에 사람들이 교류하고, 그룹 간 정보나, 장비 그리고 소프트웨어를 공유하는 방식이 구속받지는 않는다.
조직 내에서 실제로 관찰된 업무구조는 다중연결된 거미줄[web]로서, 그 상호교류가 시간이 지남에 따라 진화하는 양상이다. 이런 환경에서, 누가 새로 들어오거나 새로운 업무에 투입되면, 보통은 유용한 대화 상대가 누구인지 알기가 매우 힘들다. 어떤 편의 시설이 있는지, 그것을 어떻게 찾는지에 대한 정보는 복도에서 수군거리는 소리나, 우연히 보게 된 소식지를 통해서 알게 되고, 그걸 이용하기 위한 세부설명 또한 비슷한 방법으로 전파된다. 모든 것들을 고려할 때, 뜻하지 않는 오해나 중복된 노고에도 불구하고 그 결과물이 성공적이라는 것이 놀랍다.
한편, 사람들의 교체율이 높다는 것이 또한 문제다. 보통은 일반적인 체류기간이 2년인 상황에서, 정보는 계속 손실되고 있다. 새로운 사람이 들어오면 무엇이 어떻게 진행되고 있는가를 그가 파악하기 위해 본인 뿐 아니라 주변 사람들도 많은 시간을 써야 한다. 과거 프로젝트에 대한 세부 기술 자료들이 영원히 유실되는가 하면, 긴급 상황에서 탐정조사를 거쳐야만 복구되기도 한다. 때로는 정보가 기록은 되었으나 찾을 수 없는 상태인 경우도 있다.
CERN의 실험이 정적인 일회용 개발에 그친다면, 모든 정보가 담긴 거대한 책을 만들 수 있을 것이다. 실제로는 계속 새로운 아이디어가 나오고, 새 기술이 적용되고 있으며, 예측불가의 기술적 문제를 피해가기 위해 CERN은 끊임없이 변하고 있다. 어떤 변화가 필요할 때, 보통 조직 내부에서 영향을 받는 부분은 극히 일부다. 실험 장치나 탐지기의 일부를 교체해야 하는 국지적인 문제가 발생했다고 하자. 이 경우 다른 파트나 사람들이 영향을 받지 않을까 하는 것을 일일이 돌아다니면서 확인하는 삽질을 해야 한다. 최신 정보를 담은 책자는 비현실적이며, 이런 책자의 구조는 계속 교정되어야 한다.
우리가 답을 찾는 문제는, 예를 들어 이런 종류의 질문들이다.
정보손실 문제는 CERN에서 특별히 민감한 문제이겠지만, 이런 경우(다른 경우도 확실히 마찬가지), CERN은 몇 년 안에 나머지 세상에서 나타날 수 있는 축소판 모델이다. CERN은 현재 나머지 세계에서 곧 직면하게 될 몇몇 문제들에 봉착해 있다. 10년 안에 위의 문제들을 해결하는 많은 상업적 해법이 나올 수 있겠지만, 한편 우리가 존속할 수 있기 위한 무언가가 오늘 당장 필요한 상황이다.
링크로 연결된 정보 시스템 편집
이런 종류의 정보를 다루기 위한 시스템을 제공하려면, 어떤 조직과 함께, 그리고 정보를 통해 묘사되는 프로젝트와 함께, 성장하고 진화할 수 있도록 개발된 정보 풀을 허용했으면 한다. 이것이 가능하기 위해서는, 정보 저장 방식에서 정보에 대한 자체 제한을 없애야 한다. 이것은 링크(참조와 비슷한)로 연결된 문서들의 “거미줄 망”이 고정된 계층구조보다 훨씬 유용한 이유다. 복잡한 시스템을 설명할 때, 많은 이들이 원과 화살표로 된 그림으로 재편집한다. 원과 화살표는, 예를 들어 표를 가지고는 할 수 없는, 사물들 간의 관계를 자유롭게 기술할 수 있게 한다. 우리에게 필요한 시스템은 원과 화살표로 이뤄진 그림과 같으며, 원과 화살표는 어떤 것도 나타낼 수 있다.
우리는 이런 원을 개체, 그리고 화살표를 링크라 부를 수 있다. 각 개체가 작은 문서나 논문 요약, 또는 주석이라고 가정해보자. 그것이 글 또는 그림 또는 양쪽 모두를 포함한 것이든, 한 특정한 사람이나 물건을 묘사하거나 서술한 것이든, 여기서는 크게 걱정하지 않는다. 개체의 예로는 다음과 같은 것이 가능하다
- 사람
- 소프트웨어 모듈
- 사람들의 그룹
- 프로젝트
- 개념
- 하드웨어의 종류
- 특정한 하드웨어 기기
A 원과 B원을 연결하는 화살표는 예를 들어 A가...
- B에 의존한다
- B의 일부분이다
- B를 만들었다
- B를 참고했다
- B를 사용한다
- B의 한 예이다
이런 식의 원과 화살표, 개체와 링크는 다양한 전통적인 다이어그램에서 다른 의미로 사용된다.
다이어그램 |
개체 |
화살표 |
가계도 |
사람 |
"누구의 부모임" |
데이터 흐름도 |
소프트웨어 모듈 |
"데이터를 전달함" |
의존성 |
모듈 |
"의존함" |
PERT 차트 |
업무 |
"먼저 수행되어야 함" |
조직관리 차트 |
사람 |
"누구에게 보고함" |
이 시스템에는 어떤 종류의 정보도 입력될 수 있어야 한다. 다른 사람이 그 정보를 찾을 수 있어야 하며, 때론 그가 찾는 것이 무엇인지 모를 때도 가능해야 한다.
실제로, 어떤 위압적인 제한을 두기보다는 아이템들 사이의 링크들(예를 들어 의존성)과 개체들(사람, 사물, 자료...)의 일반적인 유형에 대해 상기시키는 것이 효율적일 것이다.
계통구조의 문제 편집
많은 시스템이 계층적으로 조직된다. CERNDOC 자료 시스템이 그 예인데, 그것은 유닉스 파일 시스템과 VMS/HELP 시스템으로 되어 있기 때문이다. 계통구조는 모든 개체에 하나의 고유한 이름을 지정해 주는 실질적인 효용이 있다. 그러나 그것은 시스템을 통해 실제 세계에 대한 모형을 얻을 수 있도록 하지 않는다. 예를 들어, VMS/HELP 시스템처럼 계층질서에 따른 도움말 시스템에서는, 종종 계통구조의 말단 지엽만을 얻게 되는 경우가 생긴다. 이를테면 이런 문장을 본다
HELP COMPILER SOURCE_FORMAT PRAGMAS DEFAULTS
참고자료라고는 또 다른 말단 지엽밖에 없다:
“Please see
HELP COMPILER COMMAND OPTIONS DEFAULTS PRAGMAS"
그래서 그 시스템을 떠나 다시 들어가야 한다. 원래 정보가 계통구조에 입력되기 위해 조직된 것이 아니어서 발생한 일이기 때문에, 이런 경우 한 개체에서 다른 개체로 연결된 링크가 필요한 것이다.
계통구조 시스템의 따른 예로는 uucp 뉴스 시스템을 들 수 있다 (Unix에서 ‘rn'을 한 번 쳐보라). 이것은 토론들(“뉴스 그룹”)의 계통적 시스템인데, 각각은 다수의 사람들이 작성한 기사를 포함하고 있다. 이것은 전문가 의견을 모아 놓을 수 있는 매우 유용한 방법이지만, 한 계보에 고정되어야 하기 때문에 불편하다. 보통, 한 뉴스 그룹에서 이뤄지는 토론은 다른 주제로 발전되고, 이럴 때 이 문건은 계보의 다른 부분으로 넘어가야 한다. (그림 1을 보라)
발신 mcvax!uunet!pyrdc!pyrnj!rutgers!bellcore!geppetto!duncan Thu Mar... 기사 93 of alt.hypertext: 경로: cernvax!mcvax!uunet!pyrdc!pyrnj!rutgers!bellcore!geppetto!duncan >발신: duncan@geppetto.ctt.bellcore.com (스코트 던칸) 뉴스 그룹: alt.hypertext 주제: 답글: 자유로운 정보 네트워크에 대한 위협 메시지-아이디: <14646@bellcore.bellcore.com> 날짜: 10 Mar 89 21:00:44 GMT 참조: <1784.2416BB47@isishq.FIDONET.ORG> <3437@uhccux.uhcc... 전달: news@bellcore.bellcore.com 답글 수신자: duncan@ctt.bellcore.com (스코트 던칸) 소속: Computer Technology Transfer, Bellcore 라인: 18
더그 톰프슨 내가 느낀 것이 검열에 대한 신중한 논점이었다고 기술한 바 있다 -- 그러나, 내가 그 점을 수용하거나 거부하는 것이 이 포스팅에 특별히 적절한 것은 아니었다.
답변에서 그렉 리는 어찌 보면 쌀쌀맞게 거부당했다.
내 질문은 (그리고 이 포스팅을 올리는 이유는) 추가 토론을 위해서는 논리적으로 이 주제를 어디서 다루는 것이 좋겠는가 하는 것이다. 어찌 보면 alt.hypertext는 적절한 장소가 아닌 것으로 보인다.
alt.individualism이나 soc 그룹 중 한 곳으로 옮기는 것이 적절하다고 느끼지 않는지. 본인은 rec.humor.funny에서 진행되는 검열 관련 특정 주제에 별 관심이 없고, 그렉의 기사에 나타난 관점에 관심 있다.
물론, 혼자 해보는 소리다, 나는... 스코트 P. 던칸 (duncan@ctt.bellcore.com OR ...!bellcore!ctt!duncan) (Bellcore, 444 Hoes Lane RRC 1H-210, Piscataway, NJ...) (201-699-3910 (w) 201-463-3683 (h)) |
그림 1. UUCP 뉴스 기구 내에 있는 한 문건
주제 필드에서 ‘뉴스 그룹’ 내에서 같은 주제에 대한 문서는 함께 묶이도록 되어있다. 뉴스 그룹의 이름(alt.hypertext)는 계층적으로 붙여진 이름이다. 이 특정의 문서는 이 기구의 엄격한 계보 구조의 문제점을 나타내고 있다: 이 토론은 몇 개의 영역과 관련이 있다. ‘참조’, ‘발신’, ‘주제’ 와 같은 필드가 모두 링크를 생성하는데 쓰여 질 수 있음을 유념하자.
키워드는 정확한 위치를 알 수 없는 자료에 접근하기 위해 일반적으로 사용하는 방법이다. 그러나 키워드의 일반적인 문제는 두 사람이 같은 키워드를 선택하지 않는데 있다. 그래서 키워드는 이미 그 응용법을 이미 잘 알고 있는 사람에게만 유용한 것이다.
실제의 키워드 시스템(예를 들어 VAX/NOTES와 같은)이 되기 위해서는 키워드들을 등록해야 한다. 이미 이것은 옳은 길로 한 걸음 들어선 것이다. 링크로 연결된 시스템은 다음과 같은 논리적 단계에 따라 이것을 수행한다. 키워드는 어떤 개념을 나타내는 개체가 될 수 있다. 그래서 키워드 개체는 다른 개체와 아무런 차이도 없다. 어떤 키워드에 문서나 기타 등등을 링크할 수 있다. 그러면 관련된 개체를 찾는 과정에서 키워드를 발견할 수 있게 된다. 이러면 비슷한 주제에 대한 문서들이 관련 키워드를 통해 간접적으로 링크되는 것이다. 이렇게 되면 키워드 검색은 몇 개의 이름 붙인 개체의 검색에서 시작되어 그것들 모두에 가까운 개체들을 찾아내는 것으로 발전한다.
이것이 내가 링크로 연결된 소규모 정보 시스템을 처음으로 만들게 된 이유였고, 당시는 이런 아이디어에 이미 “하이퍼텍스트”란 용어가 지정된 것을 모르는 상태였다.
한 가지 해결방법: 하이퍼텍스트 편집
하이퍼텍스트에 대한 개인적 경험 편집
1980년에 내가 속해있던 PS통제시스템에서 사용하는 소프트웨어 운영기록을 남기기 위해 프로그램을 하나 작성했다. Enquire라 부르는 이 프로그램은 정보의 단편들을 저장하고 관련된 부분들과 어떤 식으로든 상호 연결하는 것이 가능하도록 만들어졌다. 정보를 찾기 위해 링크를 따라 이 판에서 다른 판으로 전진해가는 것이 예전 컴퓨터 게임 “어드벤처”를 빼닮았다. 나는 이것을 사람과 모듈에 관한 나의 개인적인 기록에 사용했다. 이것은 더 최근에 애플에서 매킨토시용으로 개발된 응용프로그램 "하이퍼카드"와 유사했다. 다르다면, Enquire는 그런 화려한 그림이 없음에도 불구하고, 다수 사용자 시스템에서 돌아가고, 많은 사람들이 동일한 데이터에 접근하는 것을 허용한다는 점이다.
RPC 프로젝트에 대한 문서정리 (개념)
대부분의 정리 문서는 VMS에서 사용가능한데, CERNDOC 시스템에 저장된 두 개의 원칙 설명서를 따라야 한다.
1) includes: The VAX/NOTES conference VXCERN::RPC 2) includes: Test and Example suite 3) includes: RPC BUG LISTS 4) includes: RPC System: Implementation Guide Information for maintenance, porting, etc. 5) includes: Suggested Development Strategy for RPC Applications 6) includes: "Notes on RPC", Draft 1, 20 feb 86 7) includes: "Notes on Proposed RPC Development" 18 Feb 86 8) includes: RPC User Manual How to build and run a distributed system. 9) includes: Draft Specifications and Implementation Notes 10) includes: The RPC HELP facility 11) describes: THE REMOTE PROCEDURE CALL PROJECT in DD/OC
Help Display Select Back Quit Mark Goto_mark Link Add Edit |
그림 2. Enquire 개요 화면 일부
이 사례는 기본적으로 일종의 목록인데, 여기서는 개체에 있는 내용 자체보다 링크 목록이 더 중요하다. 각 링크가 하나의 유형으로 되어 있으며(예를 들어 "include"), 연관된 논평을 포함하고 있음에 주목하자. (맨 밑줄은 메뉴 바이다.)
CERN의 DD 부서에 다시 돌아온 후 얼마 되지 않아서, 나는 주변 환경이 PS에서와 비슷함을 발견했고, Enquire가 없어서 불편했다. 그래서 나는 VMS를 위한 버전을 준비했고, 이것을 내가 작업하는 프로젝트와 사람, 그룹, 실험, 소프트웨어 모듈과 하드웨어 장치 등의 기록에 사용했다. 나 개인적으로는 이것이 매우 유용하다는 점을 알았다. 내가 일반적인 보급판을 만들려고 하지 않았는데도, 이미 몇몇 사람들이 다른 프로젝트를 여기저기 구경하고, 자신들의 구미에 맞는 모든 종류의 것들을 찾는데 성공적으로 이 프로그램을 사용하고 있음을 알게 되었다.
주목지점 편집
그동안 상업적으로나 학술적으로 이런 생각을 발전시킨 프로그램들이 여럿 있었다. 그 대부분은 문서 안에서 아이콘이나 밝게 보이는 문장처럼 “주목지점”을 민감한 영역으로 사용해서, 주목지점을 마우스로 건드리면 관련된 정보를 내놓거나, 그것을 포함한 글을 스크린에 펼쳐 보여주는 것이다. 그래서 현재 문서에 있는 참조들이 모두 그것을 참조하는 것에 대한 네트워크 주소를 가지고 얽혀 있기 때문에, 현재 문서를 읽는 동안에 한 번의 마우스 클릭만으로 그들에게 넘어갈 수 있다고 보면 된다.
“하이퍼텍스트”는 1950년대에 테드 넬슨이 이름붙인 것으로, 지금은 이런 시스템 때문에 유명해졌지만, 원래는 다른 두 가지 아이디어를 수용하기 위해 사용된 것이다. 첫 번째 의미의 개념(지금 다루는 문제와 관련되어 있다) : “하이퍼텍스트”: 사람이 읽을 수 있는 정보가 자연스러운 방법으로 연결된 것.
다른 의미는 이와는 독립적이며 주로 기술과 시간이 해결해줄 문제인데, 그림, 연설, 동영상 등을 포함한 멀티미디어 자료에 대한 것이다. 비록 내가 문서에 국한되지 않는 경우를 지칭하기 위해 “하이퍼미디어”라는 용어를 사용하겠지만, 여기서는 후자의 측면을 더 이상 언급하지 않겠다.
그동안 한 기관에서 대규모 하이퍼미디어 시스템을 도입했을 때의 효과를 측정하기가 어려웠는데, 많은 경우 그런 시스템이 진지하게 대규모로 이용된 사례가 없기 때문이다. 그래서 어떤 새로운 정보관리 시스템을 사용하건 관계없이, 기존의 대규모 정보에 접속이 허용되도록 요청하는 것이다.
CERN의 필요조건 편집
CERN의 환경에서 실용적인 시스템이 되기 위해서는, 분명히 몇 가지 실질적인 필요조건들이 있다.
네트워크를 가로지르는 원격 접속 편집
CERN은 여기저기 흩어져 있어서, 멀리 떨어진 기기를 이용한 접속이 필수적이다.
이질성 편집
같은 데이터에 다른 유형의 시스템(VM/CMS, 매킨토시, VAX/VMS, 유닉스)에서 접속하는 것이 필요하다.
중앙 집중이 아닌 방식 편집
정보 시스템은 작게 시작해서 성장한다. 또한 고립 상태로 시작해서 통합되기도 한다. 새로운 시스템은 기존 시스템에 어떤 중앙 통제나 조정 없이도 링크로 상호 연결될 수 있도록 허용해야 한다.
기존 데이터에 접속 편집
기존 데이터베이스에 접속했을 때 하이퍼텍스트 형식인 것처럼 보여 질 수 있다면, 시스템은 더 빨리 비상할 수 있을 것이다. 이 문제는 아래에서 좀 더 다루겠다.
개인전용의 링크 편집
누구나 공개 정보에 자신의 개인전용 링크를 가고 오는 양 방향으로 추가할 수 있어야 한다. 또한 개체뿐 아니라 링크에 대해서도 개인적인 주석을 달 수 있어야 한다.
종과 호각[있으면 편리한 것] 편집
단적으로 말해서, ASCII 문서로 저장하고, 24×80 스크린에서 보이는 것이면 충분하고, 그게 중요하다. 현재로는 그림을 추가하면 접근이 매우 어려워지는 별도 선택사항이 될 것이다.
데이터 분석 편집
링크가 입력된 대규모 하이퍼텍스트 데이터베이스가 있는 경우, 흥미로운 점은 그것이 일정한 자동 분석을 가능하게 한다는 것이다. 예를 들어, 자료 분류가 안 된 소프트웨어나 사람이 포함되지 않은 구획과 같은 예외 상황을 검색하는 것이 가능해진다. 바뀐 내용을 알려야 하는 메일링 리스트 명단처럼, 사람이나 기구의 목록을 다른 용도로 추출해 낼 수 있게 된다. 또한 어떤 조직이나 프로젝트의 위상을 관찰하고, 그것이 어떻게 관리되어야 하는가, 어떻게 진화해 갈 것인가를 결론짓는 일이 가능해진다. 이것은 데이터베이스가 매우 커지고 여러 프로젝트를 결합시킨 경우, 이를테면 지나치게 꼬여 있어서 나무를 보되 숲을 보기가 힘든 상황에서 특히 유용하다.
CERN처럼 복잡한 곳에서는 사람들을 그룹으로 분류하는 일이 항상 쉽지는 않다. 사람을 작은 작은 구로 나타내고, 무언가를 공동으로 작업하는 사람들을 선으로 연결하는 대규모 삼차원 모델을 만든다고 상상하자.
그 구조를 파헤쳐 흔들어서 엉켜있는 가운데 의미 있는 무언가를 얻어내려 할 때: 아마, 어떤 곳은 단단하게 얽혀진 그룹이 있는가하면, 다른 곳에는 단지 소수의 사람들만이 걸쳐있는 교류가 취약한 지역이 보일 것이다. 어쩌면 링크로 연결된 정보 시스템은 우리가 일하는 조직의 실감나는 구조를 보여줄 것이다.
살아있는 링크 편집
어떤 링크(또는 주목지점)가 지칭하는 데이터가 매우 안정된 상태일 수도 있고, 임시로 설정된 것일 수도 있다. 많은 경우 시스템의 상태에 대한 CERN 정보는 항상 변하고 있다. 하이퍼텍스트는 자료가 “살아있는” 데이터에 연결되는 것이 가능하도록 하기 때문에, 어떤 자료에 링크가 따라올 때마다 정보가 되살아난다. 약간의 불편을 감수한다면, 링크를 따라서 특별한 응용프로그램, 예를 들어 진단 프로그램 같은 것이 정비 안내서에 직접 연결되어 작동하도록 할 수 있다.
불필요 조건 편집
하이퍼텍스트 논쟁이 때로 복제 금지나 데이터 보안 문제에 부딪치기도 한다. CERN에서는 보안보다 정보 교환이 훨씬 더 중요하기 때문에 이런 문제는 부차적이다. 하이퍼텍스트를 위한 매우 정밀한 인증과 계정 설정 시스템이 신뢰할 만한 수준에서 고안될 수 있으나, 여기서는 제시하지 않겠다.
실질적으로 안전장치가 된 문서에만 참조가 걸리는 상황이라면, 현재의 파일 보호 시스템으로도 충분하다.
특별한 응용사례 편집
다음은 제안된 시스템이 지금 즉시라도 유용하게 사용될 수 있는 세 가지 특별한 사례이다. 그 외에도 많이 있다.
개발 프로젝트 자료정리 편집
원격 처리절차 요청 프로젝트는 Enquire를 이용하는 상황을 개략적으로 보여준다. 제한되어 있긴 하지만, 이것은 누가 무엇을 하고, 그들이 어디에 있으며, 어떤 문서가 있는 지 등을 기록하는데 매우 유용하다. 또한 사용자 흔적을 기록하고, 손에 들어왔지만 어디에 놓아야 할 지 모르는 약간의 추가정보를 쉽게 목록으로 정리할 수 있게 된다. 사람과 자료에 대한 정보를 담고 있는 다른 프로젝트나 데이터베이스에 대한 교차 링크는 매우 유용해서 정보의 중복을 줄여준다.
자료 복구 편집
CERNDOC 시스템에서는 자료 저장과 인쇄 기능이 제공된다. 링크로 연결된 시스템은 개념들, 문서들, 시스템과 저자들 사이를 여기저기 탐색하는 것을 허용하면서 동시에 문서들 간의 참조 결과를 저장할 수 있도록 한다. (한번 문서가 발견되면, 인쇄 또는 화면보기를 위해 구비된 기기들을 불러와서 구동한다.)
“개인적 기능 명세서” 편집
개인적인 기능이나 경험은 하이퍼텍스트의 융통성이 필요한 영역이다. 사람은 자신이 일하는 프로젝트에 링크로 연결되고, 그 프로젝트가 이번에는 특정 기계나 프로그램 언어 등에 링크될 수 있다.
하이퍼미디어에 대한 기술 현황 편집
대학이나 사기업의 연구소에서 하이퍼미디어 연구조사에 투입되는 작업량이 늘어나고 있으며, 어떤 상업적인 시스템은 결실을 맺기도 했다. 하이퍼텍스트 ‘87과 ’88로 불리는 두 번의 컨퍼런스가 열렸고, 워싱턴에서는 국립표준기술연구소(NST)가 하이퍼텍스트 표준화 문제를 놓고 워크숍을 주최하였으며, 다음 회의는 1990년 중에 열릴 예정이다.
하이퍼텍스트에 대한 ACM 특별 쟁점 발표[the Communications of the ACM special issue on Hypertext]에는 하이퍼텍스트 논문들에 대한 많은 참조가 실려 있다. [NIST90]에 하이퍼텍스트에 대한 출판 목록이 있고, uucp 뉴스그룹인 alt.hypertext도 있다. 따라서 본인은 그 리스트를 여기 열거하지 않겠다.
탐색 기술 편집
많은 학술 연구가 복잡한 정보 공간 내에서 정보탐색을 하는 사용자 접속환경 측면을 중심으로 이뤄졌다. 언급된 문제는 탐색 경로를 쉽게 하고, “하이퍼 공간에서 길을 잃는” 상황을 피하는 문제와 같은 것들이었다. 연구 결과가 흥미롭기는 해도, CERN의 많은 사용자들은 원시적인 단말기를 이용해 이 시스템에 접속할 것이기 때문이, 향상된 윈도우 스타일은 지금 우리에겐 그다지 중요한 문제가 아니다.
상호교류인가 아니면 출판인가? 편집
오늘날 사용되는 대부분의 시스템은 단일 데이터베이스를 쓴다. 이것에 다수의 사용자들이 흩어진 파일 시스템을 이용해서 접속한다. 여기에는 각기 다른 데이터베이스에 있는 개체 사이를 링크로 연결함으로써, 말 그대로 광대한 “자료 세상”[docuverse = document + universe]를 구축하려는 테드 넬슨의 아이디어를 수용한 결과물이 거의 없다. 그러기 위해서는 일정한 표준화가 필요하다. 그러나 표준화 워크숍에서 강조된 것은 교환 가능한 미디어의 형식을 표준화하자는 것이지, 정보망을 표준화하자는 것이 아니었다. 하이퍼미디어 정보를 예컨대 광학 디스크 같은 방식으로 출판하자는 쪽의 강력한 압력 때문에 이렇게 된 것이다. 어떤 하이퍼시스템도 반드시 사용해야 하는 이상적인 데이터 모델이 합의되어야 할 것으로 보인다.
많은 시스템들이 불행히도 편리성 측면을 소홀히 하거나 완전히 무시한 상태에서 병존해 왔다. 어떤 것들은 비록 출판되었지만 외부에 개방되지 않는 독점 소프트웨어다. 그러나 몇몇은 흥미로운 프로젝트였고, 줄곧 더 많은 것들이 나타났다. 예를 들어 Digital사의 “복합 자료 체계” (CDA)는 하이퍼미디어 모델로 발전 가능한 데이터 모델이고, 아마 Digital사가 원하는 방향을 제시한 것이 아니냐는 소문이 있다.
촉진정책과 CALS 편집
미국 국방부는 앞으로 정부조달 문서를 하이퍼미디어 문서로 지정한다고 사실상 밝힘으로써, 하이퍼미디어 연구에 큰 촉진제가 되었다. 이것은 방위 물자의 각 부분 설명서가 모두 하이퍼미디어 형식으로 제공되어야 한다는 의미다. CALS는 “컴퓨터로 지원되는 물자수급과 병참지원[Computer-aided Acquisition and Logistic Support]”의 약자다.
또한 출판 산업 쪽과 정보를 조직하는 일이 직업인 도서관 사서들로부터 많은 지원이 들어오고 있다.
이 시스템은 어떤 모양으로 보일 것인가? 편집
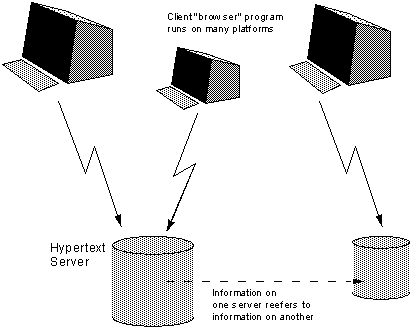
CERN에 있는 하이퍼텍스트 시스템이 어떤 구성요소를 가져야 하는지를 살펴보자. 충분히 탄력적으로 운영하기 위한 유일한 방도는 정보 저장 소프트웨어와 정보 노출 소프트웨어를 잘 정의된 경계면으로 분리시키는 것이다. 정보망에 접속하는 요청이 받아들여지면, 사용자와 멀리 떨어진 데이터베이스 기기 사이의 물리적 간격에 해당하는 인터페이스도 사라지게 하는 게 자연스럽다.
이런 구분은 CERN에서 필요한 이질성을 허용하기 위해서도 (그리고 전체 세계에 혜택이 될 수 있기에) 매우 중요하다.
그림 2. 분산 하이퍼텍스트 시스템을 위한 클라이언트/서버 모형
{kind=link}
그래서 이런 인터페이스를 정의하는 것이 시스템을 구상할 때 중요한 단계가 된다. 그런 다음, 다양한 형식의 노출 프로그램과 데이터베이스 서버 개발이 동시에 진행될 수 있게 된다. 과거, 현재 그리고 미래의 많은 다양한 정보 출처들이 그 설명 과정 위에 자리를 정하고, 다양한 사용자 인터페이스 프로그램들이 새 기술과 표준의 혜택으로 세월을 뛰어 넘어 기술될 수 있다면 이 작업은 잘 이뤄진 것이다.
기존 데이터에 접속하는 일 편집
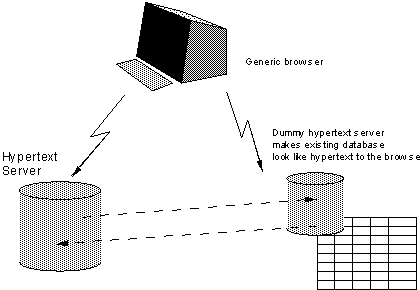
이 시스템은 조속한 시일 내에 일정수준 이상의 유용성을 확보해야 한다. 기존 하이퍼텍스트 시스템은 독자적으로 새로운 데이터에 맞춰 수정되어야만 했다. 그러나 이미 모든 전체 데이터의 기초가 될 만한 것이 존재해 왔는데, 예컨대 여기에는 새로운 데이터가 링크로 연결될 수 있으며, 각각의 새로운 데이터 조각은 더 큰 가치를 가지게 된다.
지금 필요한 것은 하이퍼텍스트 모델 위에 기존 구조를 자리 잡도록 하고, 이에 대한 제한된 접속(아마 읽기 전용)을 허용하는 출입 프로그램이다. 이것은 기존 정보를 표준 인터페이스에 맞는 형식으로 제공하도록 작성된 하이퍼텍스트 서버의 형태를 띠게 된다. 그 서버가 실제로 기존 데이터베이스에서 새로운 하이퍼텍스트 데이터베이스를 생성한다고 생각하지 말기를 : 오히려 기존의 데이터베이스를 하이퍼텍스트로 보여준다고 봐야 한다.
그림 3. 하이퍼텍스트 출입구는 기존 데이터를 하이퍼텍스트 브라우저를 통해 하이퍼텍스트 형식으로 보이도록 한다.
{kind=link}
다음은 이런 방식으로 연결될 수 있는 시스템의 몇 가지 사례이다.
uucp 뉴스
- 이것은 유닉스전자의 토론 시스템이다. uucp 뉴스 서버는 같은 주제의 글들 사이의 링크를 만들 뿐 아니라 토론의 구조를 보여준다.
VAX/Notes
- 이것은 디지털사의 전자 토론 시스템이다. 페르미 연구소에는 매우 넓은 지지층이 있으나 CEN에는 사용자가 훨씬 적다. 토론의 위상이 매우 범위로 제한된다.
CERNDOC
- 이것은 CERN의 VM 기기에서 작동되는 문서의 등록과 배포 시스템이다. 문서, 카테고리와 프로젝트처럼 키워드와 저자들이 하이퍼텍스트의 개체로 자신을 나타낼 수 있다.
파일 시스템
- 이것은 어떤 파일도 다른 하이퍼텍스트 문서로부터 링크로 연결되는 것을 가능하게 한다.
전화번호부
- 심이어 이것조차 사람과 구역 사이, 구역과 그룹 사이, 그리고 사람들과 건물의 층 사이를 연결하는 링크를 통해 하이퍼텍스트로 보여 질 수 있다.
유닉스 안내서
- 컴퓨터 가독 문서의 거대한 체계로서, 최근에는 단조로운 방식으로 구성되었지만, 이 또한 표준 형식으로 링크 정보를 담을 수 있다. ("그 외에도..")
데이터베이스
- 추측컨대 일종의 상업적인 DBMS를 사용하는 어떤 데이터베이스도 하이퍼텍스트 형식으로 보여 지도록 만들어진 포괄적인 도구인 듯.
어떤 경우는 이런 서버를 구축하는 것이 흩어진 자료를 정돈하거나 and/or 파일 형식으로 구축된 기존 통신규약에 대한 세부 정보를 얻는 의미가 있다. 하이퍼텍스트를 거치면서 고유 시스템이 가진 완벽한 기능성을 모두 제공하는 것이 비현실적일 수도 있다. 보통은 일반인들이 읽기 전용으로라도 접속하는 것이 보다 중요하다: 정보를 제공하는 사람이 제한된 소수인 경우, 일반인들은 있는 기능을 사용하는데 만족할 수도 있다.
때로 서버가 하이퍼텍스트 표현 방식을 산출해 낼 수 있음을 알고, 기존의 저장 시스템에 하이퍼텍스트 정보 코드를 삽입함으로써 기능을 향상시키는 것이 가능한 경우도 있을 것이다. 예를 들어 ‘뉴스’ 기사에는 (그 글 내에) 표준 형식으로 다른 기사에 대한 참조를 집어넣을 수도 있을 것이다. 이게 하이퍼텍스트 출입 프로그램에서 추출되어, 지칭하는 문서에 대한 링크를 생성하는데 사용될 수 있게 된다. 이런 종류의 기능 향상을 통해 낡은 것과 새 것으로 이뤄진 시스템의 집합체가 더욱 커지는 것이 가능할 것이다.
정보 처리 시스템은 언제나 굉장히 많은 종류가 있겠지만 - 우리는 그들을 교차링크 시킬 수 있기 때문에 큰 효용성을 더하게 된다. 그러나 그것들을 강제로 제한하면 우리 자신이 큰 손해를 입게 되는데, 그것은 일반적으로 사용되는 시스템들을 배제하고 하이퍼텍스트의 진화를 방해하기 때문에 생길 것이다.
결론 편집
우리는 링크로 연결된 만국 공통의 정보 시스템을 지향해야 하며, 여기서는 화려한 그래픽 기술과 복잡한 부가 기능보다 보편타당성과 편의성이 더 중요하다.
누군가 중요하다고 느끼는 정보나 참고사항을 찾기 위해 어떤 곳이든 방문해서 그것을 찾을 수 있는 길을 열어주는 게 목표다. 그 결과물을 사용하는 일은 충분히 매력적이어서, 이런 정보가 포함된 시스템 전체가 임계 문턱을 넘어서 성장할 수 있고, 그래서 계획된 대로 효용성이 나타나 반대로 그것을 더 많이 사용하게 될 수 있다.
이 문턱을 넘어가는 일은 기존의 거대한 데이터베이스가 새로운 것들과 링크로 상호 연결되도록 허용할 때 빨리 진척될 것이다.
한 가지 실천적인 프로젝트 편집
여기서 나는 CERN에서 실현가능한 해법을 찾아내기 위해 나아가는 실천적인 단계를 제안한다. 앞서 잠깐 언급한 필요조건 목록 다음에는, 당연히 산업계에서는 무엇이 가능한지가 조사 되어야 한다. 이 지점에서, 우리는 다음과 같이 미래를 보장할 시스템을 구하게 될 것이다:
우리는 이것을 약간의 변형을 통해 얻을 수도 있고, 우리가 필요로 하는 시스템과 같은 것을 다양한 출처로부터 섞어서 얻을 수도 있을 것이다: 예를 들어, 한 쪽에서는 브라우저를 그리고 다른 쪽에서는 데이터베이스를 끌어내는 식 말이다.
내가 보기에 두 사람이 6에서 12개월 정도 작업하면 프로젝트의 현재 상황을 처리하는데 충분할 것이다.
두 번째 상황은 CERN에 있는 많은 기기들에 실제로 적용되는 모종의 프로그램작업을 포함할 것이 거의 확실하다. 여기서 중요한 점은, 나중에 토론 되겠지만, 기존 데이터를 포함한 하이퍼텍스트 시스템의 집합체를 구성해서, 만국 공통의 시스템을 제공하고, 가능한 초기 단계에서 임계 효용성을 이끌어 내야 한다는 점이다.
(.. 그리고 물론, 이 과정이 진행되면서 동시에, 우리가 새로운 과제를 수행함에 따라 프로그래밍 기술을 향상시키는 굉장한 프로젝트가 마련될 것이다.) TBL[팀 버너스 리의 약자] 1989년 3월, 1990년 5월
참고 문헌 편집
[NEL67]
- Nelson, T.H. "Getting it out of our system" in Information Retrieval: A Critical Review", G. Schechter, ed. Thomson Books, Washington D.C., 1967, 191-210
[SMISH88]
- "Smish, J.B and Weiss, S.F,"An Overview of Hypertext",in Communications of the ACM, July 1988 Vol 31, No. 7,and other articles in the same special "Hypertext" issue.
[CAMP88]
- Campbell, B and Goodman, J,"HAM: a general purpose Hypertext Abstract Machine",in Communications of the ACM July 1988 Vol 31, No. 7
[ASKCYN88]
- Akscyn, R.M, McCracken, D and Yoder E.A,"KMS: A distributed hypermedia system for managing knowledge in originations", in Communications of the ACM , July 1988 Vol 31, No. 7
[HYP88]
- Hypertext on Hypertext, a hypertext version of the special Comms of the ACM edition, is avialble from the ACM for the Macintosh or PC.
[RN]
- Under unix, type man rn to find out about the rn command which is used for reading uucp news.
[NOTES]
- Under VMS, type HELP NOTES to find out about the VAX/NOTES system
[CERNDOC]
- On CERNVM, type FIND DOCFIND for infrmation about how to access the CERNDOC programs.
[NIST90]
- J. Moline et. al. (ed.) Proceedings of the Hypertext Standardisation Workshop January 16-18, 1990, National Institute of Standards and Technology, pub. U.S. Dept. of Commerce
[글 원문] http://www.w3.org/History/1989/proposal.html
{kind=link}
실례지만, 이 파일의 설명란에 ‘목적에 부합하는 자유로운 사용을 허용’한다고 적어 두셨는데, 이에 대한 자세한 근거를 여쭤보고 싶습니다.
보다 자세히 말하자면 ‘목적’이 무엇을 뜻하는지, ‘자유로운 사용’의 범위는 정확히 어디까지인지, 또한 이러한 허락을 어떻게 받으셨는지 (가능하다면 이를 증명할수 있는지 포함) 등입니다. 한국어 위키백과는 저작권이 ‘자유’로움이 명백한 자료가 아니라면 업로드가 금지되어 있습니다. 위키백과:그림의 저작권 표시 등에서 이러한 내용을 확인할 수 있습니다. 이 사실이 확실히 설명되지 않는다면 유감이지만 삭제될 수도 있습니다. 귀찮으시더라도 협조를 해 주신다면 대단히 감사하겠습니다. -- 정한솔 2009년 4월 3일 (금) 20:47 (KST)
{kind=link}
- 비슷한 그림을 1번에서 30번까지 올리신거 같네요. 다른 그림들도 같이 설명해주시면 감사하겠습니다. -- 정한솔 2009년 4월 3일 (금) 20:59 (KST)
- 이 그림들은 http://www.computerhistory.org/internet_history/에 올라 있는 사진들입니다.
내용을 번역해서 위키에 올리려고 하다보니, 사진을 업로드 하는 것이 보기 좋을 것 같아서... 이 사이트의 http://www.computerhistory.org/terms/ 부분을 참고하면 이런 내용이 나와 있네요.
Copyright
The Computer History Museum (CHM) allows anyone to use or copy content from this site consistent with the defined fair use exceptions of United States copyright laws. CHM also hereby permit students currently registered in a bona-fide educational institution anywhere in the world to make use of such content for purposes directly relating to their studies, provided no profit or remuneration is gained from any work, including such a use or copy, and provided appropriate scholarly references are given in which the source is listed as "Computer History Museum." For citation purposes, the relevant URL, prefixed by "http://www.computerhistory.org..." is recommended to allow legitimate checking and future citation of such sources.
In the case of imagery obtained from this web site, and used only as permitted above, images may be copied or distributed provided each and every such image bears the following credit line: "Image courtesy of Computer History Museum." This credit line must appear along either the vertical or horizontal margin of said image(s) or in a List of Illustrations or Table of Figures within the same document in which they are used. No images or content in any form from this site may, in any manner or by any means, be used for commercial purposes without written permission from the Computer History Museum.
Please contact CHM for copyright and licensing information at media@computerhistory.org. Thank you for respecting the rights of the Computer History Museum and other copyright holders.
Tazo 2009년 4월 3일 21:06
- 답변 감사합니다. 회신이 늦은 점 죄송합니다.
- with the defined fair use 라는 부분이 있는데, 이 부분(보다 정확히는 'fair use')에 문제가 있습니다. 이 문제는 복잡하고 아직도 한국어 위키백과 내에서 논쟁이 계속되고 있는 부분입니다만, 우선 현재의 상황을 말씀드리자면 FAIR USE는 한국어 위키백과에서 허용되지 않습니다. -- 정한솔 2009년 4월 11일 (토) 01:51 (KST)